科学大数据工程(三期) 让数据“活起来、动起来、用起来”
| 来源:【字号:大 中 小】
近日,《中共中央 国务院关于构建数据基础制度更好发挥数据要素作用的意见》(“数据二十条”)发布,是充分实现数据要素价值、促进数据经济发展的重要举措。通过构建面向流通的数据基础设施,使数据不再是深藏地下的未知财富:加强数据分析能力建设,让数据活起来;在创新环境里有序流转,让数据动起来;真正服务重大科学问题,让数据用起来。中科院“十四五"期间部署了科学大数据工程(三期),开展科学数据资源网络和科学数据流协同能力建设,促进科学数据跨中心流通和分析利用,让数据“活起来”“动起来”“用起来”,赋能数据密集型科研范式、融合科学范式,激发科学数据资源价值,服务科研创新。
一、让数据“活起来”
通过几十年的积累,中科院已经积累了超过百PB的科学数据,这些科学数据得到了规范化的管理和长期保存。然而,数据有了,工具在哪儿?特别是随着科学装置计算能力、野外台站观测能力等的大幅提升,这种分析处理需求接近实时,数据动态处理分析的需求就日益迫切。科学数据流协同能力采用集约化的建设模式,在现有大数据流水线引擎PiFlow等工作的基础上,将普遍存在于各领域相似的数据处理逻辑、经典算法模型抽象为可复用的处理组件,进而构建可跨学科领域共享使用的公共组件库。领域用户可以直接调用这些公共组件构建自己的数据分析工作流,避免重复实现底层的或经典的数据处理逻辑,更好的聚集科研业务本身。
二、让数据“动起来”
当前的科学研究往往需要多学科数据的综合支持,科研人员找数据常常“东奔西走”,解决重大科学问题时,更是需要“集团作战”。例如,在黄河流域生态保护研究,研究人员需要利用分布于若干沿黄机构的遥感、生态、气象、农业、经济数据资源及分析模型,构建综合性的数据专题及研究模型。如何打造科学数据的合力,让数据、计算协同起来,是进一步发挥科学数据价值的重要挑战。为此,科学数据流协同能力建设构建了一种端到端的科学数据协同分析框架BigFlow,通过“移动代码不移动数据”的方式实现海量科学数据的本地化分析,通过跨中心任务调度机制实现对多中心分析结果的综合分析,从而兼顾分析效率和复杂多学科跨领域场景需求,让科学数据有序流转。
三、把数据“用起来”
数据的价值最终还是要从应用中实现,中科院的科学数据工作始终坚持问题导向、任务导向,把数据应该用到科学问题中。科学数据流协同能力建设同样坚持以领域需求为导向,通过与“黄河中上游生态保护”“生态领域跨台站中心协同质控”等场景深度对接,研发适用于这些场景的公共组件库,并结合领域的协同分析需求,开展端到端科学数据协同分析框架的场景验证,在实践中促进技术研发,以技术研发促进应用示范,确保协同工作流平台能够解决领域专家的技术痛点,切实在领域应用中发挥不可替代的作用。
“数据是新型生产要素”“数据基础制度建设事关国家发展和安全大局”。在科学研究、科技创新领域,数据的价值相对其他行业领域更为显著。科学数据公共服务建设,应成为“数据基础制度建设”的重要一环。我们将把科学数据流协同能力的建设作为落实党中央决策部署的具体举措,通过构建这一关键科学数据公共服务,促进多学科跨领域科学数据资源融通,提升科学数据利用率,保障重大科研课题的研究效率。
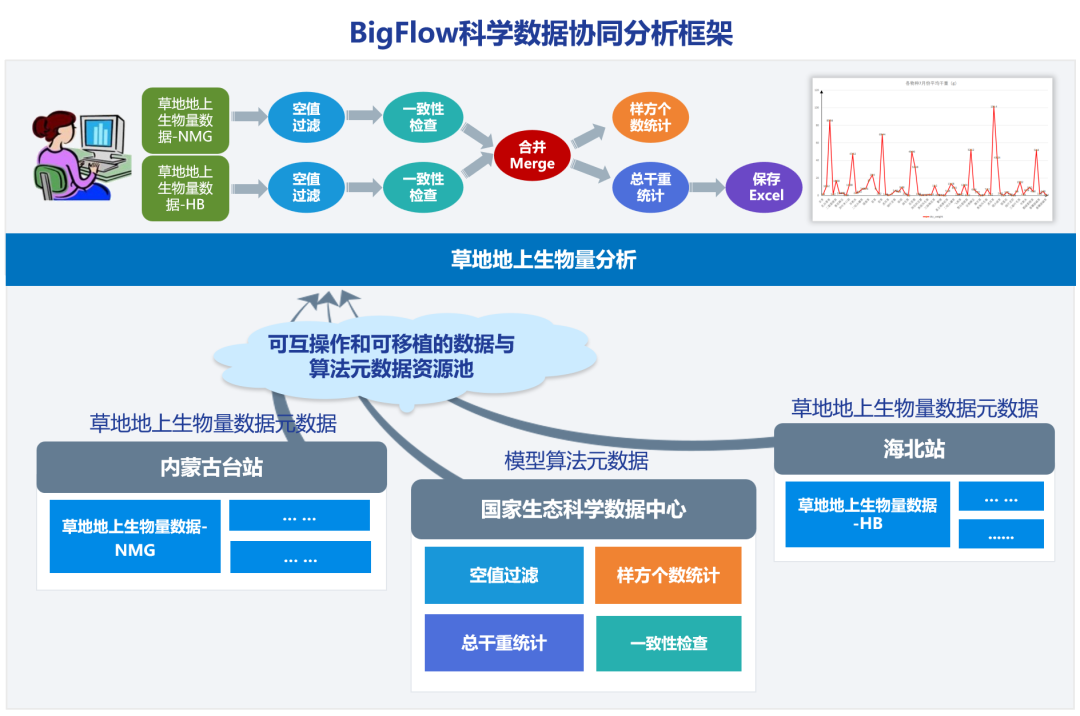
草地地上生物量跨中心协同分析案例

跨中心科学数据流协同分析需求与方案研讨

